の続きです。
今回はデータをグラフにしてどんなもんか見てみたいと思います。
glimpse関数で変数名をデータの内容を確認します。

glimpse関数はstr関数と同じような働きをします。
prefのデータは都道府県ですね。各都道府県でデータの数に違いがあるのでしょうか?

1行目は都道府県の数をtable関数で作成して、as.data.frame関数でデータフレームにしています。
2行目のmutateはprefという変数とnという変数を作成しています。
3行目のggplotでggplotのオブジェクトを作成して、
geom_barで棒グラフを作り、
coord_flipで縦軸と横軸を反転させて、
themeで軸のラベルの文字の大きさを調整しています。
そして、できたグラフがこちら、

東京は23区の他に立川市とかありますから数が多いです。京都府が一番少ないです。
cityはスキップして、regionも同じようにしてみます。

こんどはgroup_byでregionごとにして、
summarise関数でregionの数を数え、
mutate関数の中でreorder関数で数の多い順にregionを並び替えてから
ggplot以下で棒グラフを作りました。
できたグラフがこれです。

関東が一番多く、四国が一番少ないです。
eastwest(東日本と西日本)も同じようにします。


西日本のほうが東日本よりも多いです。
japanpacific(日本海側、太平洋側、その他)はどうでしょうか?


太平洋側が多く、日本海側が少ないです。
yearはどうでしょうか?
yearから後の変数は全部、数値データなので、ヒストグラムで見てみましょう。


どの年も同じ数だけデータがあるのではなくて、バラツキがあります。2015年が一番多く、1985年が一番少ないです。
koutuu(10万人当りの交通事故件数)はどうでしょうか?

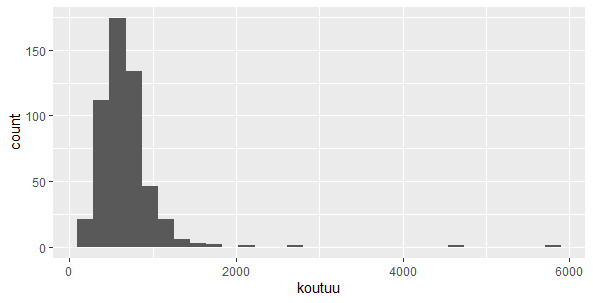
大きな外れ値がありますね。
X軸を対数にしてヒストグラムを描きます。

scale_x_continuous(trans = "log10")でX軸が対数になります。

左右対称に近づきました。
keihou(人口千人当りの刑法犯認知件数)のヒストグラムです。


keihouもkoutuuと同じく大きな外れ値があります。
こんどは軸を対数にするのではなくて、値そのものを対数変換してからヒストグラムにしてみます。


keihouのほうがkoutuuよりも右側に分布が広がっているようですね。
今回は以上です。